理解T-SQL : Where 子句,ORER BY,GROUP BY,UNION及其它
时间:2010-09-17 来源:英雄不问出处
1. Where子句说明
| 运算符 | 用法示例 | 说明 |
|
=,>,<,>=,<=,<>, !=,!<,!> |
<列名>=<另一个列名> | !=和<>都是不等于的意思,!<与!>表示不小于与不大于的意思 |
| AND,OR,NOT | <列1>=<列2> and <列3>=<列4> | 优行级的次序为:NOT>AND>OR |
| BETWEEN | <列1> BETWEEN 1 AND 5 | 表示值在…范围之内 |
| LIKE | <列1> LIKE “ROM%” | %,_表示通配符:%表示一个或多个任意字符,_表示单个任意字符。[a-c]表示或a或b或c, ^和NOT表示一个字符被排除 |
| IN | <列1> IN (数字列表) | IN关键字左边的值与IN关键字右边给出的列表中的任何值匹配,返回True,常常在子查询中使用 |
| ALL,ANY,SOME | <列|表达式>(比较操作符)<ANY|SOME>子查询 | ALL表示左值必须与结果集中的所有值匹配,ANY与SOME等价,表示表达式与结果集中任何值匹配则返回true |
| EXISTS | EXISTS(子查询) | 子查询至少返回一行,返回TRUE。 |
以上,子查询在后面的章节中会细述。
2.ORDER BY
ORDER BY是用来对查询结果进行排序,使用方法为ORDER BY <列名1>,<列名2>…[DESC]
以上注意的是,可以基于多个列来进行分类排序。这是我以前没有用过的。
3.GROUP BY
GROUP BY用来聚集信息。对于统计一些数据非常有用。比如,以下SQL,用来查询某个人的订单所有的运费信息:
select LastName,FirstName,Freight from Orders O,Employees E where O.EmployeeID=E.EmployeeID
得到的结果如下所示:
LastName FirstName Freight
-------------------- ---------- ---------------------
Buchanan Steven 32.38
Suyama Michael 11.61
Peacock Margaret 65.83
Leverling Janet 41.34
Peacock Margaret 51.30
Leverling Janet 58.17
Buchanan Steven 22.98
Dodsworth Anne 148.33
Leverling Janet 13.97
Peacock Margaret 81.91
Davolio Nancy 140.51
Peacock Margaret 3.25
Peacock Margaret 55.09
Peacock Margaret 3.05
Callahan Laura 48.29
OK,我想要查询每个人的总运费已经花了多少(对某个字段进行统计),就可以使用GROUP BY子句来进行:
select LastName,Sum(Freight) as TotalFreight from Orders O,Employees E where O.EmployeeID=E.EmployeeID group by LastName
得到的结果如下:
LastName TotalFreight
-------------------- ---------------------
Buchanan 3918.71
Callahan 7487.88
Davolio 8836.64
Dodsworth 3326.26
Fuller 8696.41
King 6665.44
Leverling 10884.74
Peacock 11346.14
Suyama 3780.47
所以,当考虑到聚集时,会经常与Group By子句一起使用。常用的聚集包括:
AVG: 计算平均值
MIN/MAX:最小数字和最大数字
COUNT(表达式/*) :获取一个查询中的行数 –> select count(*) from Employees
4. HAVING 子句
where子句是对相应的表中的列数据进行限定,应用到每一行上。而HAVING是对聚集进行限定,应用到组的聚集值上。
通过一个示例将为明白两者区别,下面的语句将得出总运费超出¥5000的人的列表:
select LastName,Sum(Freight) as TotalFreight from Orders O,Employees E where O.EmployeeID=E.EmployeeID group by LastName having Sum(Freight)>5000
以上,得到的结果如下所示:
LastName TotalFreight
-------------------- ---------------------
Callahan 7487.88
Davolio 8836.64
Fuller 8696.41
King 6665.44
Leverling 10884.74
Peacock 11346.14
5. DISTINCT 修饰符
DISTINCT是用来消除重复数据的,如果值是相同的,则该值只出现一次。如果与COUNT()使用,则只计算一次。
它应用的地方有两处:要么应用于Select开始列表处,希望没有重复的行,要么出现在COUNT函数内部,用来消除重复数据计算。
例如,以下语句,找到订单表中所有下过订单客户的信息:
select DISTINCT customerID from orders
6. 使用UNION联接表
UNION并不像JOIN关键字一样是个真正的联接,它更像是从一个查询直接向另一个查询进行数据追加。
JOIN是水平的合并数据(基于多个表,添加更多的列),而UNION是垂直的合并数据(基于多个表,添加更多的行),如图所示:
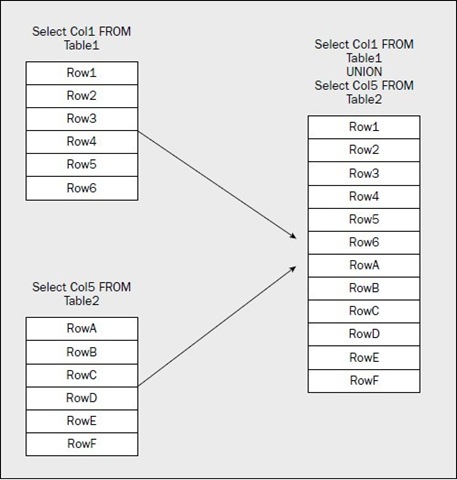
以下使用UNION需要注意的地方:
a. 所有进行UNION的查询,Select列表中列的数量必须相同。
b. 为合并的结果集返回的标头仅取自第一个查询。如select Col1,Col2 as Second,Col3 from Table1 Uncion select Col4,Col5,Col6 from Table2;那么它返回的标头列肯定是Col1,Second,Col3
c. 一个查询中的每一列数据类型必须与其它查询中对应的列的数据类型隐式兼容。
d. UNION默认返回的方式是DISTINCT而非ALL,除非指定了ALL关键字,否则,只返回一个有重复的行
select col1 from t1 uncion all select col2 from t2; –> 这样就能返回所有的行了。
相关阅读 更多 +