HubbleDotNet 开源全文搜索数据库项目--为数据库现有表建立全文索引(二) Updatable 模式
时间:2010-08-30 来源:eaglet
HubbleDotNet 可以非常方便的对数据库现有表或视图创建全文索引,整个过程人工干预的时间不超过5分钟。我将用几个篇幅来阐述如何对现有数据表创建全文索引。本篇将重点介绍如何创建 Updatable模式的全文索引。
Updatable 和 Append only 的共同点都是被动模式建索引,其区别在于采用 Updatable 模式为数据库现有表建立的全文索引可以添加,修改和删除,而 Append only 模式只能做添加和删除(Append only 模式删除不能自动,要通过程序来删除),不能修改。Updatable 模式索引同步要比 Append only 复杂很多,详见自动和现有表同步,所以如果你的表只是进行添加和删除操作,没有修改操作,建议用 Append only 模式,否则用 Updatable 模式。
在对现有表创建全文索引前,我们还是需要先在 HubbleDotNet 中创建一个数据库,如何创建数据库见:HubbleDotNet 开源全文搜索数据库项目--创建、删除数据库
创建好HubbleDotNet的数据库后就可以开始对关系数据库中现有表或视图建全文索引了。
下面我以Test库的EnglishNews 表为例,讲解如何针对现有表创建全文索引。
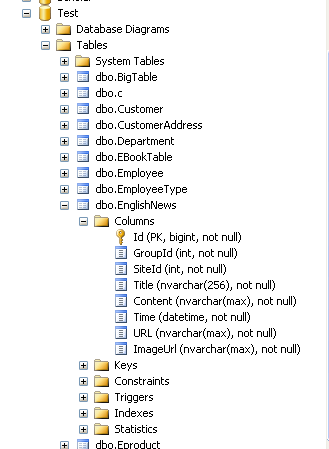
这是SQL SERVER的 Test库中 EnglishNews 表的结构
在HubbleDotNet 中建索引表
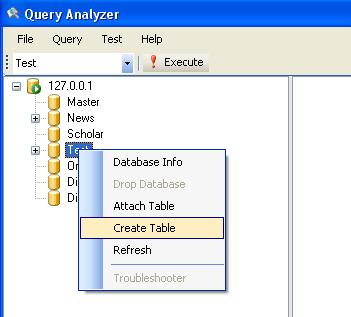
打开查询分析器,在News 库这个节点点右键选 Create Table,如下图所示
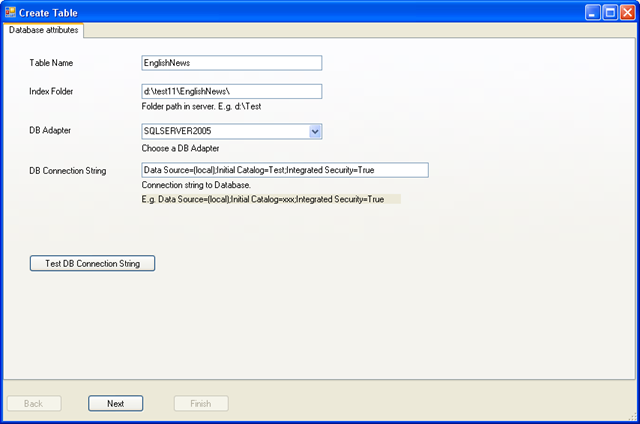
如上图所示点击Create table 后会出现这个界面,按照界面提示,输入HubbleDotNet 的表名,这里输入 EnglishNews,这个名字不一定要和数据库的名字相同。 再输入全文索引所在目录,选择数据库适配器,这里由于我对应的关系数据库是SQLSERVER 2005,所以选SQLSERVER 2005, 这个适配器适用于SQL SERVER 2005 及以后的所有版本。然后再配置一下关系数据库的连接字符串,这个连接字符串用户和对应的关系数据库连接,如果需要连接远程数据库,只需要在这里指定Data Source = 远程IP地址就可以了。点下面的Test DB Connection String 按钮测试连接字符串没有问题,点Next 进入下一步。
选择索引模式

如上图所示,由于是被动索引模式,我们选择 Build Index from exist table
Exist table Name or View Name 这里输入数据库中对应表的表名,这里输入 EnglishNews。 由于HubbleDotNet 不但可以对现有表做索引,也可以对视图做索引,所以如果被索引的不是表而是视图,只要在这里填写数据库中对应的视图名就可以了。
由于这个表不但要添加删除,还要修改,这里我们选择增量模式为 Updatable 模式。
点Next 进入下一步
配置索引字段
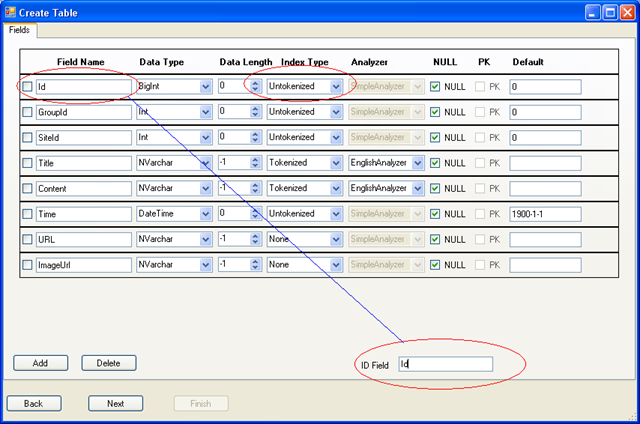
如上图所示,HubbleDotNet 会自动从数据库中读取表结构,帮助用户生成索引表结构。
Updatable 类型索引,数据库的现有表必须有一个Int 或 Bigint 类型 Id 字段(ID Field) 这个字段的字段名可以为除DocId以外的任意名字。这个字段必须设置为Untokenized 索引类型。这个字段必须是自增长的。
如果被索引的表的主键不是int或bigint 类型,比如vchar 类型字段做主键,那么我们必须在被索引表中插入一个 int 类型或bigint 类型的自增长字段,并为这个字段建唯一性索引,然后将 ID Field 指向这个字段才行。
设置完所有字段后,点击下一步
完成索引
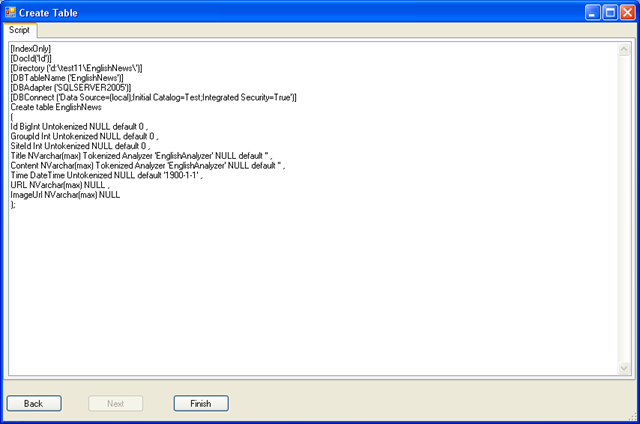
这一步列出创建语句,你可以做最后的检查,如果确认没有问题,点Finish。建表语句如下,你也可以不通过建表界面,直接写建表语句来建立索引表。
[IndexOnly]
[DocId('Id')]
[Directory ('d:\test11\EnglishNews\')]
[DBTableName ('EnglishNews')]
[DBAdapter ('SQLSERVER2005')]
[DBConnect ('Data Source=(local);Initial Catalog=Test;Integrated Security=True')]
Create table EnglishNews
(
Id BigInt Untokenized NULL default 0 ,
GroupId Int Untokenized NULL default 0 ,
SiteId Int Untokenized NULL default 0 ,
Title NVarchar(max) Tokenized Analyzer 'EnglishAnalyzer' NULL default '' ,
Content NVarchar(max) Tokenized Analyzer 'EnglishAnalyzer' NULL default '' ,
Time DateTime Untokenized NULL default '1900-1-1' ,
URL NVarchar(max) NULL ,
ImageUrl NVarchar(max) NULL
);
这时将提示

如果你打算马上就开始索引,选 Yes
这时将进入 Rebuild Table 界面

点Rebuild 就可以开始为EnglishNews 这个现有表创建全文索引了。
这里需要注意的是:
Updatable 模式只能对空索引进行Rebuild,就是说如果HubbleDotNet 中已经有了这个表的索引记录,哪怕只有一条,就不能再继续 Rebuild 了,这时
只能点 RebuildWholeTable 对全表的索引清空后重新Rebuild。如果想在原来索引的基础上增量或修改,需要使用HubbleDotNet 提供的自动同步功能来完成。
如何用自动同步功能,见:自动和现有表同步

全文索引建立完以后,我们可以优化一下,如下图所示
优化完以后,就可以搜索了。(不优化也可以搜索,性能会慢一些)
下面看看怎么搜索
搜索新闻
示例1
搜索标题包含 abc news to cut 这几个关键字中任意一个关键字的所有记录,并按匹配度排序
SQL 语句:
select top 10 Id, Title, Score from EnglishNews where title match 'abc^5000^0 news^5000^3 to^5000^7 cut^5000^9' order by score desc
结果:
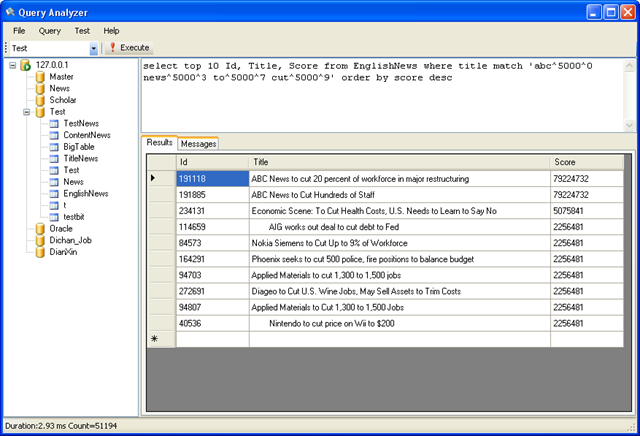
单词分量后面跟的参数含义如下
第一个参数表示这个单词分量的权值,这里为5000。
第二个参数表示这个单词分量在输入的被搜索的句子中的其实位置,如这里“abc”的位置为0,news的起始位置为 3.
top 10 表示输出前10条匹配的记录
这里可以看出,完全匹配的记录,得分最高。
示例2
搜索标题包含 abc news to cut 这几个关键字中所有关键字的记录,并按匹配度排序
SQL 语句:
select top 10 Id, Title, Score from EnglishNews where title contains 'abc^5000^0 news^5000^3 to^5000^7 cut^5000^9' order by score desc
结果:
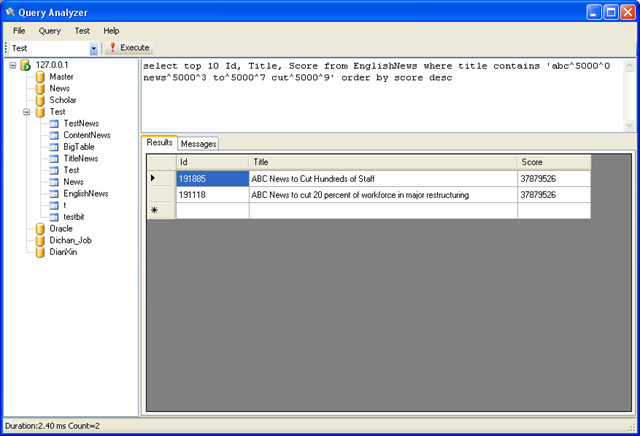
采用 Contains 搜索,可以进行精确匹配,这里我们发现采用 Contains 搜索出来的数据要比 Match 少很多。因为只有同时包含abc news to cut 这四个单词的记录才会被输出出来。
再进一步,由于 to 这个词太常见,我们希望匹配同时包含 abc news cut 这三个单词的记录,并且记录中如果包含 to ,则得分比不包含to 的得分高。这种搜索方法已经很解决 google 或 baidu 的搜索方法了,google 中如果输入关键字中包含停用词,对非停用词采用与的方式匹配,对停用词采用或的方式匹配,但如果记录中包含要匹配的停用词,则得分比不包含的要高。
SQL 语句:
select top 10 Id, Title, Score from EnglishNews where title contains 'abc^5000^0 news^5000^3 to^5000^7^1 cut^5000^9' order by score desc
结果:

这里我们看出,多出了一条记录,这条记录排在第三位,和前两条记录比起来,这条记录没有 to 这个单词。
to 这个单词分量后面跟的参数说明:
to^5000^7^1
前两个参数和其他单词的意思一样,一个为权重,一个为位置。
第三个参数为标志字段,1 表示可以为或。
示例2
搜索标题包含 abc news to cut 这几个关键字中任意一个关键字的记录,并按匹配度排序,同时按 GroupId 字段做统计,输出记录最多的10个groupid
SQL 语句:
[GroupBy('Count', '*', 'GroupId', 10)] select top 10 Id, Title, Score from EnglishNews where title match 'abc^5000^0 news^5000^3 to^5000^7 cut^5000^9' order by score desc
结果:
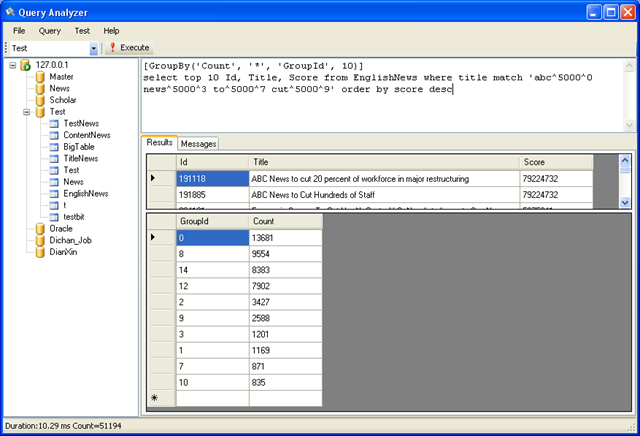
最后一个参数 10 是可选参数,表示返回前10个最多的分组统计结果,如果不填,返回所有分组统计结果。
Group By 字段必须为 untokenized 类型索引字段且不能是字符串类型。
这个语句执行后,会输出2个DataTable 第一个是 select 语句的结果集,第二个是group by 的结果集。也就是说在全文搜索时同时进行分组统计,这样使用起来更方便,而且速度更快。
再进一步
[GroupBy('Count', '*', 'GroupId', 10)] [GroupBy('Count', '*', 'SiteId', 10)] select top 10 Id, GroupId, SiteId, Title, Score from EnglishNews where title match 'abc^5000^0 news^5000^3 to^5000^7 cut^5000^9' order by score desc

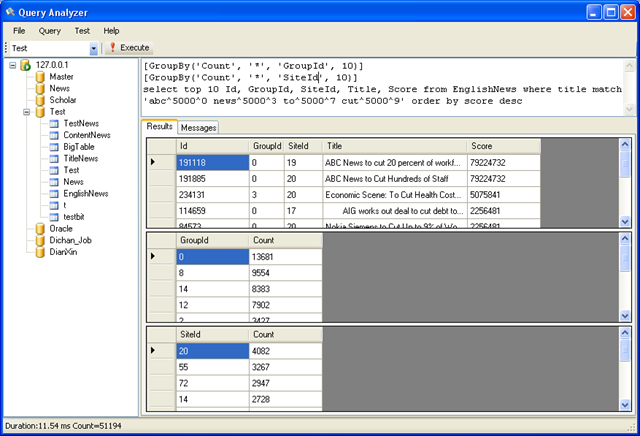
这个语句同时输出正对 GroupId 和SiteId 两个字段的统计结果。很多电子商务网站需要在搜索的同时显示多个分组的统计结果,HubbleDotNet 可以通过上面语法一次输出
出来。而且HubbleDotNet 的 GroupBy 功能是在底层进行统计的,比Lucene 的统计需要在结果输出后再通过程序进行过滤统计要简单快速很多。
GroupBy 部分的伪SQL 语句是
select top 10 GroupId, count(*) as count from englishnews where title match 'abc^5000^0 news^5000^3 to^5000^7 cut^5000^9' group by GroupId order by count desc
再进一步
[GroupBy('Count', '*', 'GroupId,SiteId', 10)] select top 10 Id, GroupId, SiteId, Title, Score from EnglishNews where title match 'abc^5000^0 news^5000^3 to^5000^7 cut^5000^9' order by score desc
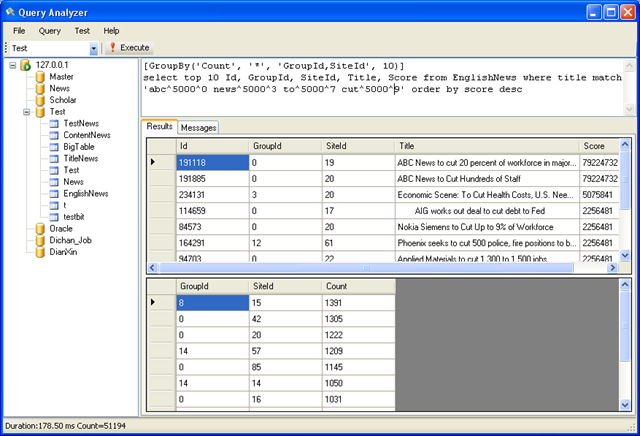
上述语句可以针对多个字段进行分组统计。要注意的是多字段 GroupBy 时,多个字段的占用字节数总和不可以超过8字节。及最多2个int类型,或者8个tinyint类型。
更多例子见 HubbleDotNet 开源全文搜索数据库项目--为数据库现有表或视图建立全文索引(一) Append Only 模式
相关阅读 更多 +